2 ORD Project Plan
The following sections explain our approach in greater detail. Though working packages can be seen as stages in general, they are not strictly sequential as some activities are continuous efforts. This chapter gives an overview that shows responsibilities within the team and intensitvity of activities throughout the project.
2.1 WP0: Coordination and Planning
Activity 0.1: Meetings with data provider management and operations
Activity 0.2: RSEED workshop series
RQ 0.1: Which channels and formats work to keep the dialogue active and sustainable?
RQ 0.2: How can we integrate usage of publicly available data into teaching?
During the starting stage of our project, we coordinate with major public data providers and involve data sources. We will do this to establish and maintain active, lively communication between public data providers and the scientific community.
Publicly available economic data provided by the Federal Statistical Office (FSO), the Secretariat of Economic Affairs (SECO), the Swiss National Bank (SNB), and regional Statistical Offices are important sources for economic research and monitoring of the Swiss economy. To develop an ORD spirit and a community of data providers and scientific users of the data, it is crucial to involve these public institutions early on. Early dialogue and our experience from developing an ORD community in the openwashdata project (Schöbitz, Dr. Elizabeth Tilley, and Matthias Bannert, n.d.) helps to avoid redundancies with existing data community initiatives and to develop a common understanding of open data, machine readability and datasets of priority.
One core idea is to leverage existing, general investment into publicly available economic data through integration of public data into academic teaching to strengthen the connection between public administration and academia. In the sense of our open source spirit, we look to add further Research Data Management (RDM) aspects to our existing, freely reusable, CC-BY licensed online teaching.
To explore how to effectively use the joint expertise of public data providers, domain experts, data stewards of the ETH domain, and data engineers, we will launch a series of monthly workshops early in the process. The workshops are designed to foster inclusive, expert discussions through publicly pre-circulated content. We are working to integrate our workshop series into the academic curriculum at ETH, but we keep the series open to interested participants beyond academia.
2.2 WP1: Make Data Processing Framework Inclusive
Activity 1.1: Implement core library for standardized data processing
Activity 1.2: Modularize provider specific data ingestion processes
Activity 1.3: Document processing framework
RQ 1.1: What are the key components of a framework to ingest data for scientific use?
RQ 1.2: How can we isolate idiosyncrasies for optimal reuse of code?
RQ 1.3: What makes documentation of open source software and open research data inclusive?
In Work Package 1 (WP1), we lay the technical foundation for turning KOF Swiss Economic Institute’s existing production process of macroeconomic time series into an open-source framework that creates publicly available, machine-readable, scientific-grade time series in a fully reproducible fashion. Our approach uses open-source software licenses that are free of license costs and aims to publish not only the resulting time series data but also the technical framework and infrastructure setup. This ensures reproducibility and helps comply with FAIR principles. Thanks to our infrastructure-as-code approach, we can publish information on an ideal runtime environment to help others operate their own instance of the Open Time Series framework.
Because an active community is crucial to keep the project sustainable, i.e., well maintained, we chose the R Project for Statistical Computing as our main programming language for the implementation of the framework. With its annual user conferences (Joo et al. 2022) and vibrant local communities1, R is known for its large and inclusive community. Alongside its strong regional and international community, the fact that R is open source and free of license costs lowers the barrier to entrance and contribution considerably. In addition, R offers well-established boilerplating2 ecosystems like usethis (Wickham et al. 2023) and documentation frameworks such as pkgdown (Wickham, Hesselberth, and Salmon 2022) or Roxygen (Wickham et al. 2022).
WP1 focuses on the homogenization of the data ingestion process across datasets and data providers. In the first implementation step, we identify common parts of the ingestion process. We bundle these common parts in an R package that forms our core library and fosters reuse of source code. We encourage the community to use our core packages and to contribute by adding further dataset-specific packages. To inspire contributions, we supplement the Open Time Series framework’s core, based on our long-term experience as consumers of public data, with provider-specific ingestion libraries written in R that cover dataset idiosyncrasies.
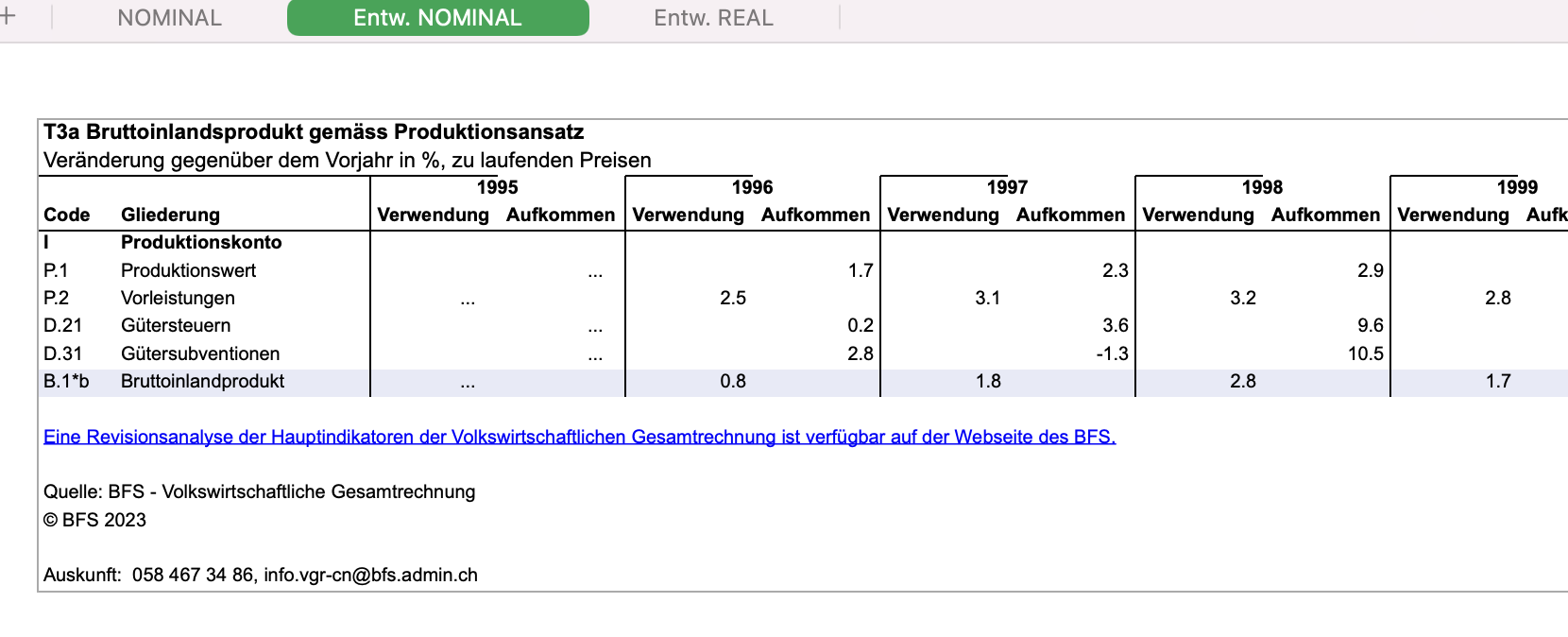
The above screenshot shows a traditional data publication of an official GDP statistic. Its use of multiple worksheets, empty lines and multi-line headers hampers machine readability. Like many regular consumers of the information contained in this spreadsheet, KOF sources this information immediately after its publication.
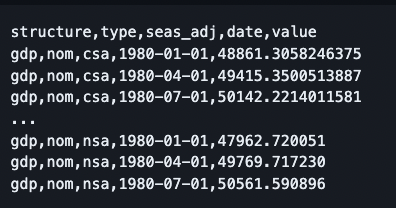
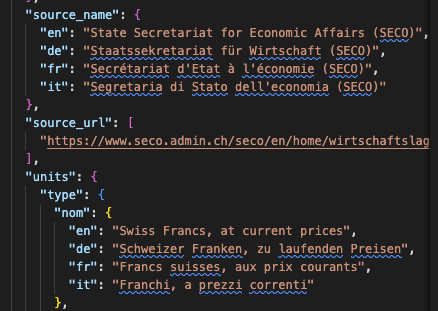
To have a homogeneous, machine-readable representation of the data, we split this information into two files: based on the Comma Separated Values (CSV) on the web idea by the World Wide Web Consortium (W3C), we use a long format CSV file for the data and a Javascript Object Notation (JSON) file for the metadata. The metadata file takes advantage of the JSON format’s ability to handle nested data to store comprehensive, multilingual meta information. Our collaboration with the Secretariat of Economic Affairs led to a pioneering pilot publication of machine-readable data on the official SECO website: Machine-readable data is published as a complement to the traditional GDP publication3.
At the end of WP1, we plan to iterate over the resulting datasets and data descriptions and enhance meta information where necessary. We will do this in a reproducible and transparent way by adding all changes to the source code that produces the data and metadata files.
2.3 WP2: Publication
Activity 2.1: Publication of data processing framework
Activity 2.2: Publish containerized runtime setup
Activity 2.3: Publish data processing and revision monitor
Activity 2.4: Publication of time series datasets for scientific use
RQ 2.1: Which publication channels foster reuse of our code in other fields?
RQ 2.2: How can we facilitate the deployment of our setup in other environments?
RQ 2.3: Which information on data revisions and processing does the scientific (forecasting) community need to benchmark their work?
RQ 2.4: Which channels help to capture the evolution of the needs of the academic community ?
The goal of Work Package 2 (WP2) is to find the platforms that suit our community, data and code components best and facilitate our approach to ORD. We will involve our data consumers and collaborators into this decision-making process. Based on our open by default thinking, we will publish not only the resulting time series data and meta information, but all components of our software framework. In the process, we will work together with the ETH legal service to find the most suitable open source licensing solution4 for all components of the opents project.
The Open Time Series project approach we suggest, splits data and meta information into two separate text files and formats: a simple CSV spreadsheet and a nested JSON file for multilingual data description. Having two simple text files per dataset allows us to disseminate the resulting time series data on free, standard infrastructure such as GitHub, which is well established in the open-source community. The state-of-the-art rendering of CSV spreadsheets on modern Git platforms sets the barrier to exploring and consuming our scientific use time series datasets as low as possible. Hence, the publication of data on GitHub, possibly using git’s Large File Storage (LFS) extension, forms our baseline scenario. Yet, in WP2, we will explore the feasibility of other, complementary, regional and international publication channels such as opendata.swiss5, r-universe or Zenodo.
Technically, the Open Time Series framework consists of a core R package and several data provider-specific ingestion packages. Again, we see the publication of all these components as open-source libraries on GitHub (or another major Git platform with good visibility) as the baseline form of publication. In addition, WP2 explores which of our components are suitable for publication on the Comprehensive R Archive Network (CRAN). Publication on CRAN comes with requirements and quality control but opens up our work to a larger audience so that endusers face the lowest possible hurdle to installing our packages.
We will also explore more recent and experimental approaches, such as r-universe which helps to improve our reach in the data science community. In WP2, we aim to submit our work to an rOpenSci (Ram et al. 2019) peer review. rOpenSci shares our values of open and reproducible research through reuse and helps us reach ORD excellence.
2.4 WP3: Facilitate Usage and Applications
Activity 3.1: Integrate Open Time Series framework and data into Hacking for Science courses
Activity 3.2: Organization of a community event
RQ 3.1: What degree of data engineering literacy do scholars from different fields of research need?
RQ 3.2: Future outlook – What are the next steps to extend Open Time Series to other fields?
The goal of work package 3 (WP3) is to promote usage of the framework and data as well as to encourage others to contribute. In particular we are looking for community contributions such as maintenance of existing datasets, addition of public datasets that have not been processed yet and community activities. At this stage, we will also intensify activities to explore the expansion of Open Time Series into other academic fields.
We plan to reach the above goals in three ways: i) integration of Open Time Series data and software into academic teaching aimed at scientists from different disciplines. ii) presentation of Open Time Series at useR! 2024 in Salzburg, Austria6. iii) participation in local community events iv) hosting of an own event at KOF.
Starting in fall 2024, Open Time Series data and software will be integrated into the Hacking for Science course7 given at ETH. Originally created for ETHZ D-MTEC PhD students, Hacking for Science is a highly interactive online course whose big picture guidance and hands-on software development approach attracts students from a great variety of fields. The course’s last iteration welcomed students from more than 10 different ETH departments as well as guests from outside ETH. Following up on previous findings about a desirable degree of technical expertise in modern empirical economics (Bannert 2022-03), we are eager to learn about the challenges ORD faces in different fields and discuss the value of open data with a broad audience of young researchers.
Currently, we also explore the possibility of running Hacking for Research Assistants – a satellite event for research assistants. In addition our teaching is complemented by the Research Software Engineering and Economic Data (RSEED) workshop series started in early 2024 which gives us an additional channel to promote an ORD mindset.
Starting with the submission of Open Time Series to useR! 2024, we plan further activity at conferences and community events. At ETH, the Scientific Computing group has recently founded a Research Software Engineering (RSE) group8 to connect software engineers in science at ETH. Regular RSE events at ETH as well as the vibrant, local open source and opendata community9 will give us a chance to present the Open Time Series project, e.g., at the RSE group or the local R user group. KOF hosted useR! in 2021 and is well connected to the R community. This history and connections give a great chance to successfully apply for hosting an existing special interest conference such as R in Official Statistics at KOF. Hosting a well-established, smaller special interest conference allows us to give the entire event an ORD focus promote ORD thinking in official statistics.
Bannert (2024 forthcoming) discusses the importance of communities for the learner, including experience from hosting the useR! Conference 2021 which KOF co-chaired.↩︎
In software development, the term boilerplate refers a unit of reusable code. Using boilerplate systems helps to homogenize code maintained by a community of maintainers.↩︎
See also: https://www.seco.admin.ch/seco/en/home/wirtschaftslage—wirtschaftspolitik/Wirtschaftslage/bip-quartalsschaetzungen-/daten.html, accessed February 12, 2024.↩︎
see https://choosealicense.com/, accessed on February 12, 2024.↩︎
https://opendata.swiss, accessed on February 12, 2024.↩︎
useR! is the annual conference of R users. In 2024, it takes place from July 7-11 and is ideally suited to kick off our project while allowing us to stay on the ground and reach a highly relevant conference by train. useR! conferences usually draw more than 1’000 international users from a large variety of fields. See also https://events.linuxfoundation.org/user/ accessed on February 12, 2024.↩︎
See also: the course announcement blog post: https://rseed.ch/posts/h4sci/ and course Kite award nomination: https://ethz.ch/en/the-eth-zurich/education/innovation/kite-award/kite-award-2022/nominierte-projekte-kite-award-2022/hacking-for-social-sciences.html accessed on February 12, 2024.↩︎
The RSE group is already well connected to the global RSE movement, partiuclarly to the Society of Research Software Engineering in the UK. See also https://rse.ethz.ch/ accessed on February 12, 2024.↩︎
see events such as opendata beer, lovedata week↩︎